Apache Spark作为大数据处理和分析领域的领先工具,正日益成为企业和组织处理海量数据的首选解决方案。本期将深入探讨Apache Spark的核心概念和框架模型。
Spark是什么
Spark是一个开源的大数据处理框架,旨在提供快速、通用且易于使用的分布式计算和数据处理能力。它由Apache Software Foundation开发和维护,构建在Hadoop生态系统之上,但相较于传统的MapReduce模型,Spark提供了更高级别的API和更广泛的功能。
Spark的主要目标是解决大数据处理中的速度和灵活性问题。它通过在内存中进行数据处理和缓存,显著提高了处理速度。Spark支持多种编程语言接口,包括Scala、Java、Python和R,使开发者能够使用自己熟悉的语言进行大数据处理和分析。
Spark框架模块
Apache Spark框架由多个模块组成,每个模块提供不同的功能和API。以下是Spark框架的主要模块:
- Spark Core:Spark Core是Spark框架的基础模块,提供了分布式任务调度、内存管理、错误恢复和与存储系统交互的基本功能。它定义了弹性分布式数据集(RDD)的概念,并提供了RDD的创建、转换和操作的API。
- Spark SQL:Spark SQL模块提供了用于结构化数据处理和SQL查询的功能。它支持在Spark中执行SQL查询,并提供了DataFrame和DataSet等高级数据结构,用于进行关系型和结构化数据的操作。
- Spark Streaming:Spark Streaming模块用于处理实时数据流。它基于微批处理的方式,将实时数据流划分为小批次,并在每个批次上进行数据处理和分析。这使得Spark Streaming能够处理实时数据,并提供可容错的、高吞吐量的实时计算能力。
- MLlib:MLlib是Spark的机器学习库,提供了丰富的机器学习算法和工具。它包括分类、回归、聚类、推荐和协同过滤等常见机器学习任务的算法实现。MLlib还提供了特征提取、模型评估和数据预处理等功能。
- GraphX:GraphX是Spark的图计算库,用于处理和分析大规模图数据。它提供了图的构建、遍历、操作和算法运算的API。GraphX支持顶点和边的属性,可以用于解决社交网络分析、推荐系统和图形算法等问题。
- SparkR:SparkR是Spark的R语言接口,允许使用R语言进行Spark应用程序开发和数据处理。它提供了基于R语言的DataFrame API,使R用户能够利用Spark的分布式计算能力进行数据分析和建模。
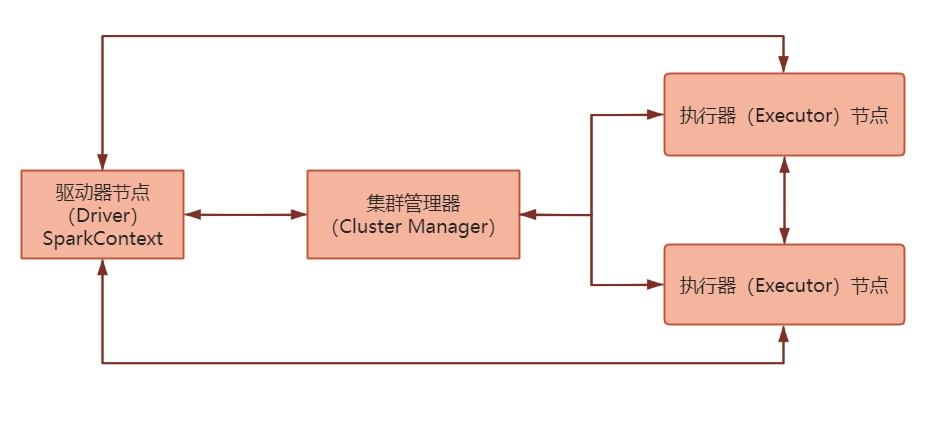
Spark集群模式架构
Spark集群模式架构通常涉及以下组件和角色:
- 驱动器节点(Driver):驱动器节点是Spark应用程序的控制节点,负责解析应用程序代码、执行任务调度、管理资源分配和协调工作节点。它通常运行在集群的一个节点上。
- 执行器节点(Executor):执行器节点是Spark应用程序的工作节点,负责执行实际的任务和计算。每个执行器节点都在独立的JVM进程中运行,并接收来自驱动器节点的任务指令。
- 集群管理器(Cluster Manager):集群管理器负责管理集群中的资源分配和任务调度。它负责将任务分配给可用的执行器节点,并监控它们的健康状况。常见的集群管理器包括Spark自带的独立模式、Apache Hadoop YARN、Apache Mesos和Kubernetes。
- 分布式存储系统:Spark需要一个分布式存储系统来存储数据和中间结果。常见的存储系统包括Hadoop分布式文件系统(HDFS)、Amazon S3、Apache Cassandra等。这些存储系统可以提供数据的高可靠性和容错性。
在集群模式下,Spark应用程序的工作流程如下:
- 驱动器节点启动:Spark应用程序的驱动器节点在集群中的一个节点上启动,驱动器程序负责加载应用程序代码、创建SparkContext对象并与集群管理器进行通信。
- 资源分配和任务调度:集群管理器根据可用的资源情况(如CPU、内存)将任务分配给可用的执行器节点。执行器节点会启动Spark执行器进程来接收任务。
- 任务执行:驱动器节点将任务分发给执行器节点,执行器节点根据指令执行相应的计算任务。它们可以在本地或远程的数据分区上执行任务,将结果返回给驱动器节点。
- 结果汇总和输出:驱动器节点收集执行器节点返回的结果,并进行汇总和聚合。最后,应用程序可以将结果写入存储系统、打印到控制台或进行其他操作。
Spark的四种运行模式
Spark 提供了多种运行模式,以适应不同的部署需求和环境。下面是 Spark 常见的四种运行模式:
- Local 模式:在本地机器上以单机模式运行Spark应用程序。这种模式适用于开发和调试阶段,不需要分布式计算和资源管理。在本地模式下,Spark应用程序将在单个JVM进程中运行。
- Standalone 模式:Spark的独立模式是一种简单的集群模式,其中Spark应用程序在独立的Spark集群上运行。该模式适用于小规模集群,可以通过Spark自带的集群管理器启动和管理。独立模式提供了资源管理和任务调度功能,可以在集群中的多个节点上并行执行任务。
- YARN 模式:Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,Spark可以在YARN上以集群模式运行。它利用YARN的资源管理和调度功能,将Spark作为YARN应用程序在Hadoop集群上运行。在YARN模式下,Spark应用程序可以与其他基于YARN的应用程序共享资源。
- Mesos 模式:Apache Mesos是一种通用的集群管理系统,可以用于在分布式环境中运行多个应用程序。Spark可以在Mesos上以集群模式运行,利用Mesos的资源隔离和调度功能。Mesos模式下的Spark应用程序可以共享Mesos集群上的资源,并与其他Mesos应用程序共存。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对YARN而言,Spark运行在Mesos上会更加灵活、自然。
Spark编程模型
Spark编程模型基于弹性分布式数据集,简称RDD,它是Spark的核心抽象概念。Spark编程模型的核心思想是基于RDD的转换和行动操作,通过构建一系列的转换操作来定义计算逻辑,然后通过行动操作来触发实际的计算和获取结果。下面来讲述一下RDD的性质:
- 什么是RDD?
RDD是一种具有容错性基于内存的集群计算抽象方法,它代表一个分布式的、不可变的、可容错的数据集合,可以在Spark集群中的多个节点上并行操作和处理。
-
RDD的五大特点
- 分区:RDD逻辑上是分区的,仅仅是定义分区的规则,并不是直接对数据进行分区操作,因为RDD本身不存储数据。
- 只读:RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
- 依赖:RDD之间存在着依赖关系,宽依赖和窄依赖。
- 缓存:如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据。
- checkpoint:与缓存类似的,都是可以将中间某一个RDD的结果保存起来,只不过checkpoint支持持久化保存。
-
如何构建RDD?
在Spark中,可以通过以下几种方式构建RDD:通过 textFile(data):Spark支持从各种外部数据源(如Hadoop HDFS、本地文件系统、数据库等)读取数据并创建RDD。可以使用
SparkContext对象的textFile方法读取文本文件,或使用其他合适的方法读取其他类型的文件。from pyspark import SparkContext # 创建SparkContext对象,并指定本地模式和应用程序名称 sc = SparkContext("local", "RDD_test") # 使用textFile方法读取文本文件并创建RDD,并将结果赋值给rdd变量 rdd = sc.textFile("D:/sparkFile/text/file.txt")通过 parallelize(data): 可以使用
SparkContext对象的parallelize方法,将一个已有的数据集合(如列表、数组等)转换为RDD。from pyspark import SparkContext # 创建SparkContext对象,并指定了本地模式和应用程序名称 sc = SparkContext("local", "RDD_test") # 创建一个数据集合data data = [1, 2, 3, 4, 5] # 使用parallelize方法将数据集合转换为RDD,并将结果赋值给rdd变量 rdd = sc.parallelize(data) -
RDD的操作
RDD支持两种类型操作,分别是转换操作(Transformations)和行动操作(Actions)。- Transformation转换操作:
转换操作是对RDD进行处理和转换的操作,它们不会立即执行,而是创建一个新的RDD作为结果。转换操作是惰性求值的,只有在遇到行动操作时才会触发实际的计算。一些常见的转换操作包括map()、filter()、flatMap()、reduceByKey()等。这些操作可以用于对RDD的元素进行映射、过滤、扁平化、聚合等操作,以便进行数据的转换和处理。 - Actions行动操作:
行动操作是对RDD进行实际计算并返回结果的操作,它们会触发RDD的计算并返回最终结果。行动操作会导致Spark执行计算图中的所有转换操作,并将结果返回给驱动程序或写入外部存储系统。一些常见的行动操作包括collect()、count()、reduce()、saveAsTextFile()等。这些操作用于触发RDD的计算并返回计算结果,或将结果保存到外部存储系统中。
- Transformation转换操作:
-
RDD的依赖关系
在Spark中存在两种类型的依赖:
-
- 窄依赖:父RDD中的一个Partition最多被子RDD中的一个Partition所依赖。
- 宽依赖:父RDD中的一个Partition被子RDD中的多个Partition所依赖。
- RDD的持久化
RDD持久化是Spark中一种重要的性能优化技术,它可以将RDD的计算结果缓存到内存或磁盘中,以便在后续的操作中重用,这样可以避免重复计算和提高任务执行效率。在Spark中,持久化RDD有两种常见的方式:
-
- RDD的缓存
缓存是将RDD的计算结果存储在内存或磁盘上的一种方式。当一个RDD的计算非常的耗时/昂贵(计算逻辑比较复杂)的时候,并且这个RDD需要被重复(多方)使用,可以考虑将该RDD的计算结果缓存起来,便于后续的使用,从而提升PySpark程序的运行效率。
-
- RDD的checkpoint检查点
checkpoint类似缓存操作,只不过缓存是将数据保存在内存或者磁盘当中,而checkpoint是将数据保存在磁盘或HDFS,主要是放在HDFS上面。一旦构建好checkpoint之后,会将RDD间的依赖关系给删除/丢弃,因为checkpoint提供了更加安全可靠的数据存储方案。后续如果计算出现了问题,可以直接从checkpoint检查点上恢复数据。
缓存与checkpoint的区别:
存储位置:
-
- 缓存: 存储在内存或者磁盘 或者 堆外内存中。
-
- checkpoint: 可以将数据存储在磁盘或者HDFS上, 在集群模式下, 仅能保存到HDFS上。
生命周期:
-
- 缓存:当程序执行完成后,或者手动调用unpersist缓存都会被删除的。
-
- checkpoint: 即使程序退出后, checkpoint检查点的数据依然是存在的, 不会删除, 需要手动删除。
血缘关系:
-
- 缓存: 不会截断RDD之间的血缘关系, 因为缓存数据有可能是失效, 当失效后, 需要重新回溯计算操作。
-
- checkpoint: 会截断掉依赖关系, 因为checkpoint将数据保存到更加安全可靠的位置, 不会发生数据丢失的问题, 当执行失败的时候, 也不需要重新回溯执行。
需要注意的是,缓存和检查点都是惰性操作,只有在对RDD进行行动操作时才会实际触发缓存或检查点的计算和存储。